The Geometry of Error: Why Loss Shapes Change
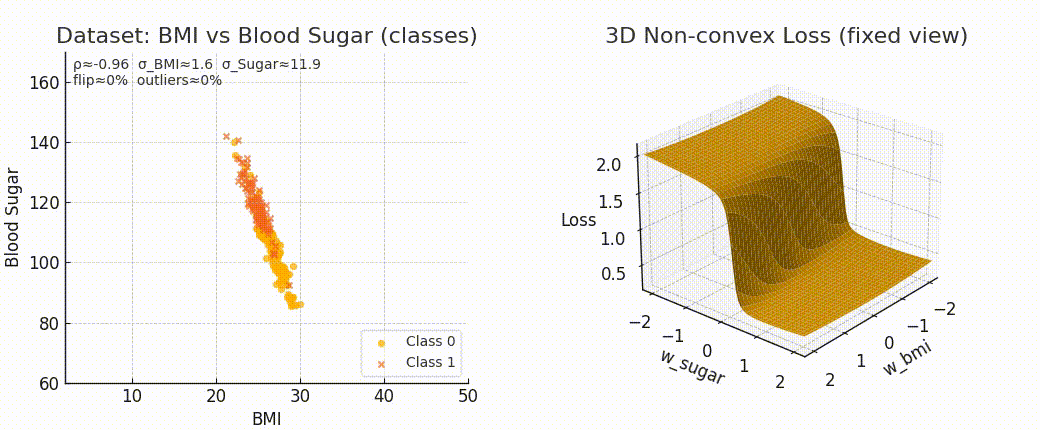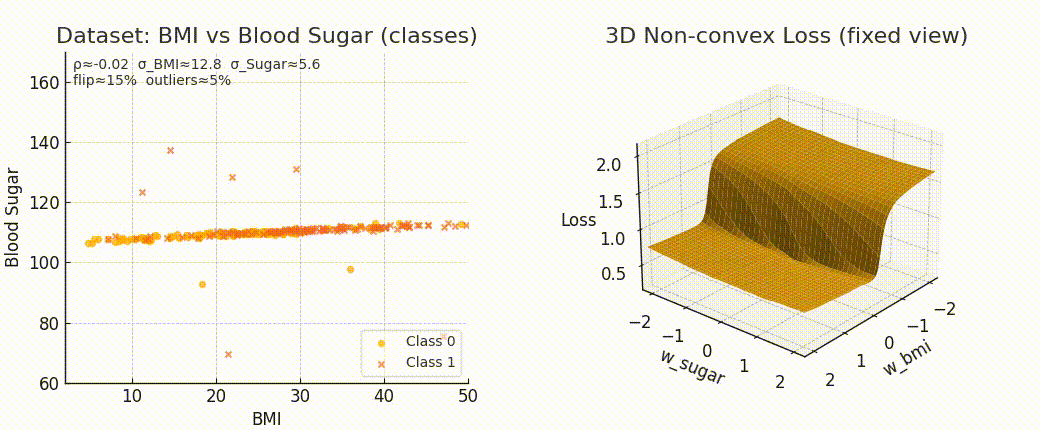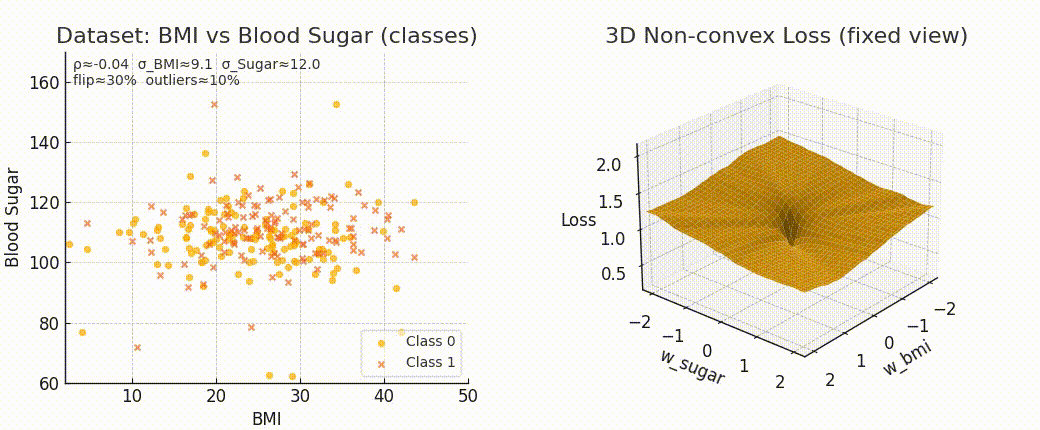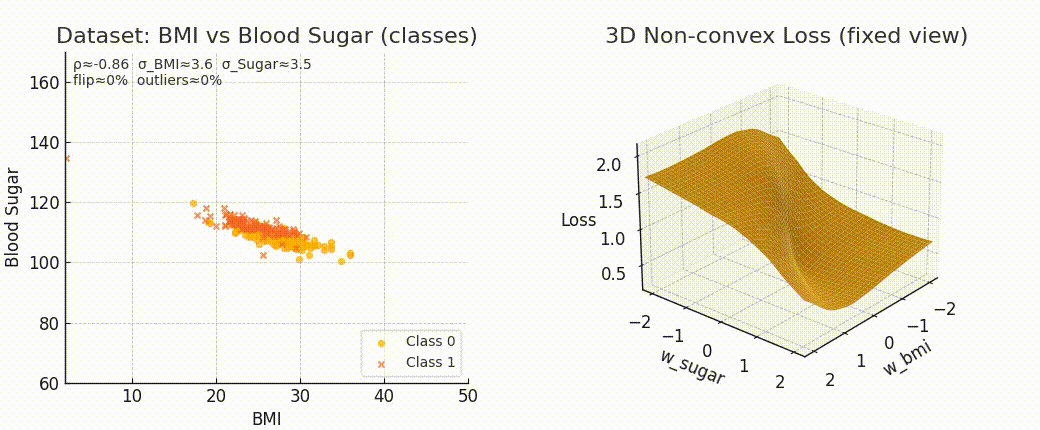
If you’ve done even a bit of Machine Learning, you know this:
ML works because of loss functions.
They give direction — literally. A loss function is the quantity the model tries to minimize. For regression, the most common choice is Mean Squared Error (MSE):
MSE = (1/n) Σ (yi − ŷi)²
It optimizes for the smallest average squared error across training points.
But here’s a deeper question:
If MSE is “the same formula”, why does optimization look different every time the dataset changes?
Let’s break it down.
yi = actual target
ŷi = predicted target
For simple Linear Regression (1 feature):
ŷi = w₁xi + w₀
So MSE becomes:
(1/n) Σ (yi − (w₁xi + w₀))²
Now notice something critical:
👉 The xi values come from the dataset.
When the dataset changes:
-
xi changes
-
yi changes
-
their distribution changes
Even though the form of MSE stays the same, the surface we optimize over completely changes.
Same loss.
Different geometry.
If data is well spread and linear → smooth bowl-shaped surface.
If data is noisy or complex → steeper curves, warped valleys.
And the more irregular the surface, the harder it is to reach the minimum.
That’s why we repeatedly need:
• Gradient Descent
• Momentum
• Adam
• Other optimization tricks
Because optimization difficulty is not just about the formula. It’s about the geometry induced by the data.
Same loss function.
Different landscape.